从 “稍后读” 到 “终身维基” :专为重度阅读者打造的个人知识内化方案。
🔗 官网
https://github.com/Kenshin/simpread-karpathy-llm-wiki-compiler
🌟 核心理念
作为 简悦(SimpRead) 的创建者,我设计了这个框架,旨在弥合 “稍后阅读(Read-it-Later)” 与 “永远不读(Read-it-Never)” 之间的鸿沟。
本项目是基于 Andrej Karpathy 提倡的 LLM Wiki 概念构建的 个人知识库自动化知识构建方案。它不仅是一套工具链,更是一种将 “被动囤积” 转化为 “主动内化” 的个人知识库自动化构建协议。
这套框架利用具备文件读写权限的 AI 环境,将任意本地 Markdown 文件(或通过简悦导出的本地的本地快照)转化为高度结构化、可溯源、且具备双向链接的个人维基(Wiki),专为处理 大规模(1000+)异步阅读素材 而生。
我使用这套框架管理着通过 简悦 (SimpRead) 收集的数千个深度阅读内容(稍后读)。它不只是简单的存储,而是通过一套 协议驱动型架构,将凌乱的 HTML/Markdown 剪藏增量编译为具备高度逻辑性、可回溯、且带有本地快照链接的结构化维基。
比 RAG 方案 更简洁,比 AI 浏览器方案 更强大,这套框架的 👉 具体使用方案
😆 太长不看
🧬 设计哲学:Karpathy LLM Wiki Protocol
-
原子化 (Atomic):知识点被拆解为最小逻辑单元。
-
原始数据驱动 (Data-Driven):Wiki 只是 Raw 素材的 “编译产物”,随原始数据的演进而进化。
-
显式溯源 (Grounding):每一条知识
wiki/均引用原始来源raw/。 -
无损演进 (Non-destructive):采用
[ADD]增量合并与[FIX]轨迹修正,完整保留知识的迭代过程。
👥 目标受众
-
理念践行者:对 Andrej Karpathy LLM Wiki 理念感兴趣,且具有大量处理大量本地文件(知识库)的用户。
-
简悦资深玩家:已配置 本地知识库 的简悦用户。
✨ 特点与优势
-
无须配置:支持开箱即用。
-
增量更新:仅处理新增或修改的文件,节省 Token 并提高效率。
-
海量处理:支持 1000 行以上的大文件以及多主题并发处理。
-
高度扩展:支持自定义技能库
skills/,轻松实现功能插件化。 -
协议与数据解耦::全部数据为文本数据,方便迁移。
-
简报模式:专门用于大量数据提取主题并生成简报,可直接生成 ASCII / Mermaid / 表格 / 关系图等结构。
🔥 相比 RAG 的优势
| 维度 | 传统 RAG (Vector Search) | Karpathy LLM Wiki (本项目) |
|---|---|---|
| 处理量级 | 面对数千个长文本时,检索结果容易产生碎片化。 | 全局掌控。 专为数千个长文设计的 “流式吞噬” 协议,逻辑不留死角。 |
| 溯源精度 | 仅定位到语义片段。 | 原子级回溯。 每个事实精准挂载 简悦本地快照链接 (Localhost)。 |
| 知识深度 | 关键词匹配,难以理解复杂的因果链。 | 深度架构。 像编译代码一样理清技术演进与产品哲学。 |
| 稳定性 | 容易受到模型幻觉和切片干扰。 | 确定性。 每一行 Wiki 都有对应的 Source 账本支撑。 |
⚠️ 处理大文件的机制
为解决大文件导致的 “信息截断” 顽疾,本方案内置了 强制分块读取流:
-
行数预检:AI 处理前会先确认原始文件的总行数。
-
循环吞噬:若超出单次处理窗口,AI 会自主执行循环分段读取(如
read_lines),直至触达文件末尾(EOF)。
📂 目录结构说明
.
├── raw/ # 原始素材库:按主题文件夹存放原始素材
│ ├── 主题A/ # 主题文件夹,每个主题文件夹对应一个 Wiki 页面(如果是简悦用户的话,每个文件夹下面有若干个序号从 0 开始的文件 e.g. `0.md`, `1.md`, ...
│ ├── 主题B/
│ ├── 主题C/
├── wiki/ # 目标知识库:编译后的 Wiki 页面 (*.md)
├── skills/ # 核心技能库
├── command/ # 常用命令
└── AGENT.md # 全局元协议:定义 AI 执行任务时的基本准则
🛠️ 技能库 (Skills) 详解
0️⃣ 全量初始化:skills/init.md
全量扫描 raw/ 根目录,在 wiki/ 创建相应的主题,建立 INDEX.md 索引锚点。
1️⃣ 添加操作:开辟新主题 (skills/add.md)
识别 raw/ 下的新主题,自动注册(在 wiki/ 创建对应 .md )至 Wiki 体系。
2️⃣ 更新操作:深化已有主题 (skills/update.md)
仅处理新增素材,执行增量追加。
3️⃣ 全量审计:skills/audit.md
对特定主题重新深度扫描,找回隐藏的逻辑关系,丰富简略段落。
4️⃣ 知识消费协议:command/qa.md
强制执行 “知识库优先” ,当内部知识库无法满足回复时,将会引用外部知识体系。
5️⃣ 快捷命令:command/ask.md
执行后,自动调用 command/qa.md 的回答规则,在之后将使用 /ask [提问内容] 提问。
6️⃣ 执行 skills 命令:command/generate.md
输入 /gen [快捷指令] 调用具体的 skills 命令。
7️⃣ 执行 skills 命令:command/report.md
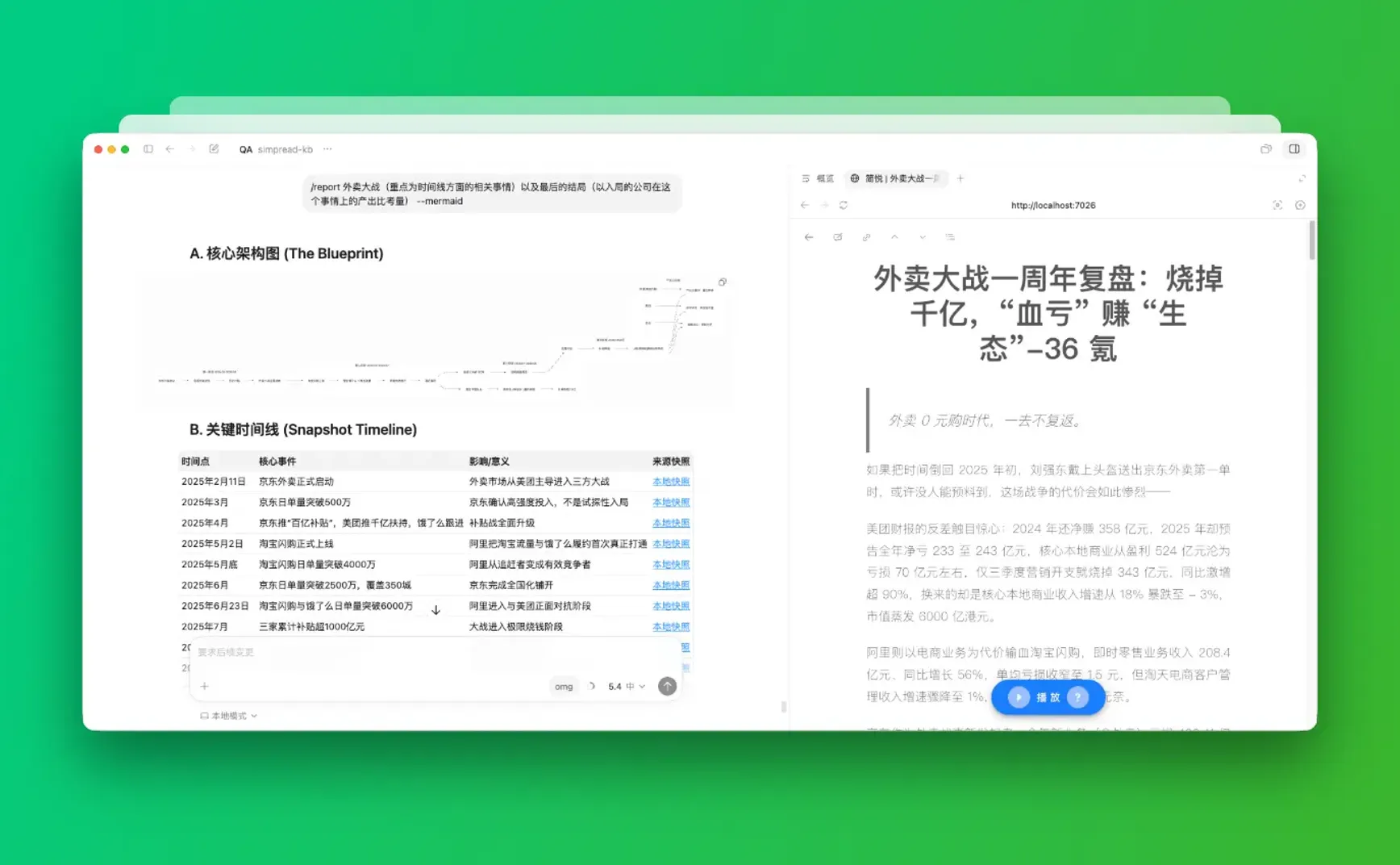
执行 /report [主题] 自动生成基于架构图的深度洞察简报。
生成图表时包含了 ASCII (默认)和 Mermaid 方案,可通过 /report -- mermaid 切换。
8️⃣ 执行 skills 命令:command/refresh.md
当修改 AGENT.md skills/ command/ 里面的内容后,需要使用此命令获取并理解这些内容。
📖 使用说明
📥 下载
git clone [email protected]:Kenshin/simpread-karpathy-llm-wiki-compiler.git 或 手动下载并解压缩到任意目录
🚀 首次使用
执行 startup.md
💡 提问
-
输入
/ask [提问内容]即可开始提问。 -
输入
/report [主题]即可开始生成对应主题的简报。
🧰 后续维护
-
添加新主题:输入
/gen add.md -
更新旧主题:输入
/gen update.md
🔎 审查(重新梳理任意主题)
当某个主题的内容较大时(如 1000 行以上,包含多个索引 .md 文件),LLM 生成的 Wiki 的知识颗粒度可能不够,这时需要使用 audit.md 进行深度审计。
-
执行
generate.md内容(仅需一次,如已执行,则无须再次使用)。 -
输入
/gen audit.md开始针对某一主题进行重新审计。
🔄 更新技能
当修改 AGENT.md skills/ command/ 里面的内容后,需要使用此命令获取并理解这些内容。
-
执行
refresh.md内容(仅需一次,如已执行,则无须再次使用)。 -
输入
/refresh全部重新扫描skills/command/的内容并重新理解和严格执行。 -
输入
/refresh [filename]开始针对某一主题进行重新审计,如/refresh audit.md仅重新理解和严格执行 audit.md。
📚 快速上手
为方便快速上手,此框架中内置了一些 Demo 数据(来自通过简悦生成的 276 篇文章,分为 47 个文件),位置在 raw/标签@科技史话_AI战争/ 下面,同时使用这套访问生成了对应的 wiki/标签@科技史话_AI战争.md
-
执行
startup.md -
提问
/ask 请以 OpenAI 为关键字,生成一份以时间线为主的简报,并按照 /report 的格式给出答案。
🌊 工作流指南
-
情况 A(新主题):素材放入
raw/→ 输入/gen add.md→ 确认报告并开始执行。 -
情况 B(更新素材):新素材丢进
raw/已有主题/→ 输入/gen update.md→ 查看变更日志。 -
情况 C(深度挖掘):如果觉得某个 Wiki 主题内容有缺失可输入
/gen audit.md后根据提示重新从/raw/[主题]挖掘。 -
情况 D(提问):输入
/ask [你的问题]。 -
情况 E(简报):输入
/report [主题]。 -
情况 F(高级用法): 输入
/ask 请在 AI 相关内容中检索 OpenAI CEO 相关内容,并按照 /report 方案整理。 -
情况 G(高级用法): 输入
/ask 请在 AI 相关内容中检索 OpenAI CEO 相关内容,并按照 /report -- mermaid 方案整理。
🖥 仅迁移到新的环境
相比 RAG 方案,此方式可以方便的迁移到任意支持本地操作的 AI 环境中。
假设你已在使用这套 LLM Wiki 了(也就是 wiki/ 积累了很多内容),当迁移到新环境中,仅需要执行 startup.md
🖼 截图
🔌 简悦用户专属配置
🛠️ 深度整合:简悦 (SimpRead) 生态
本项目针对 简悦 (SimpRead) 导出的素材进行了专项优化:
-
快照直达:完美映射简悦本地解析服务器地址 (
http://localhost:7026/...),实现从 Wiki 结论到原始阅读环境的秒级跳转。 -
元数据兼容:自动识别简悦导出的原文地址、标签及原始文件名。
-
海量吞噬:针对数千个文件可能带来的上下文溢出问题,内置了动态行数预检与分块流式读取机制。
-
简报模式:专门用户大量数据提取主题并生成简报,可直接生成 ASCII / Mermaid / 表格 / 关系图等结构。
📚 使用前提
💡 特点
确保存在本地快照即可,设置目录后,可将本地快照以各种检索方式(如标签、时间点、任意搜索内容等)进行保存到 raw/ 目录。
⚡ 在稍后读 · 极速版使用
📖 在阅读模式下使用
使用简悦插件 · 导出简悦知识库 👉 GitHub | 语雀
🤖 使用工具建议
只要是可以操作本地文件的 AI 工具均可,此工程在 Visual Studio Code · Codex · Trae · OpenCode 下完成。
分别使用了 Google Gemini Flash · GPT-5.4 · MiniMax-M2.7 模型。
🤝 贡献与反馈
欢迎 提交 Issue 或 Pull Request 来完善编译器协议。